Видео с ютуба Token Per Second Benchmarks

Fastest 1000000 tokens

LLM Speed Tiers Explained: What TPS (Token Per Second) Actually Feels Like

How to Run a Trillion-Parameter AI at 1,000 Tokens a Second

The Local LLM Lie Nobody Talks About: Why "Tokens Per Second" is a Scam for AI Agents

LLM Inference Benchmark 2026: Every GPU Ranked by Tokens Per Dollar
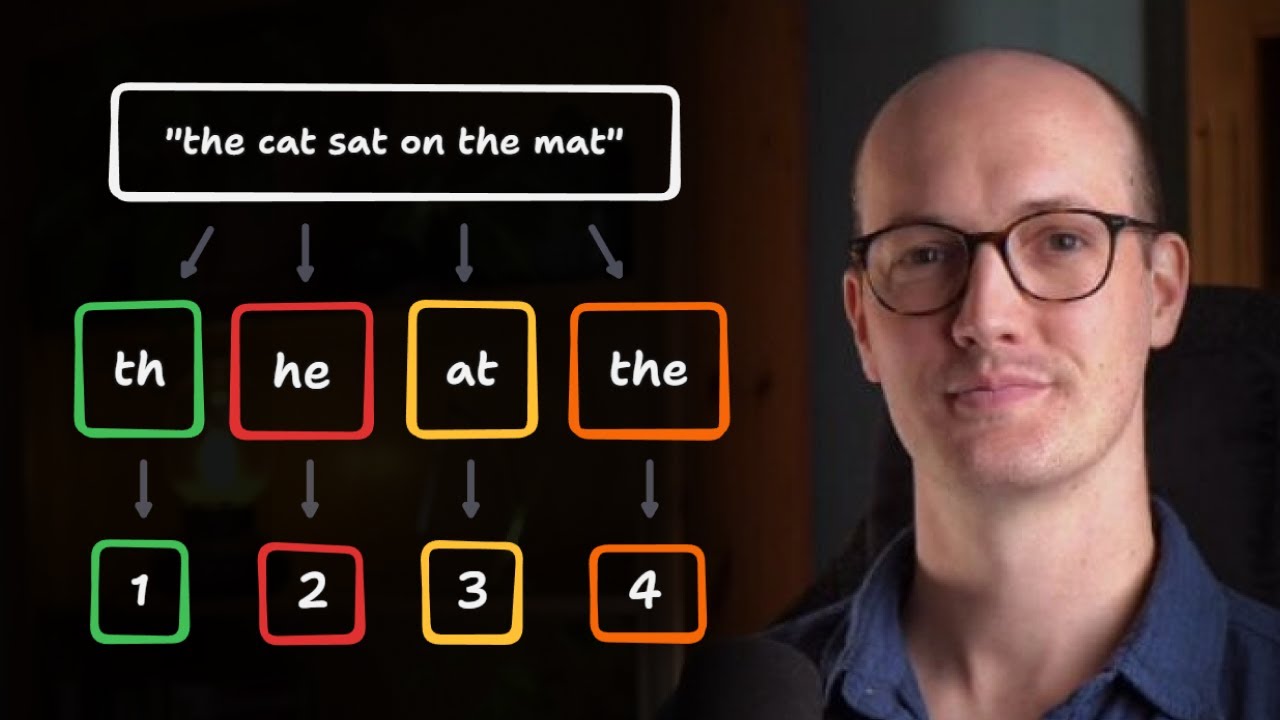
Большинство разработчиков не понимают, как работают токены LLM.

NVIDIA users: QWEN3 is FREE, but you’ll pay double

Ditch 512 GB Monster…this M3 Ultra Just Redefined “Enough”

Going up against Apple's Ultra

Mac Studio CLUSTER vs M3 Ultra 🤯

Skip M3 Ultra & RTX 5090 for LLMs | NEW 96GB KING

DeepSeek on Apple Silicon in depth | 4 MacBooks Tested

M4 Mac Mini CLUSTER 🤯

MTP в llama.cpp ускорил Qwen3.6-27B — тесты RTX 3090, 5090 и Mac